
Data teams want to reduce the workload created by ad-hoc queries. Many are exploring natural language querying solutions to lower the barrier to entry for data querying and effectively eliminate the time-suck that basic data questions create. But they have a decision to make first. Which of their data should they target?
Nothing on the market has solved the challenge of offering seamless, AI-powered insights into structured and unstructured data simultaneously. Some traditional BI tools can store both, facilitating manual analysis— even then, only experienced analysts will be comfortable doing this.
Platforms like Tableau are hard to use as a beginner, with static dashboards and minimal flexibility to manipulate data. Snowflake has expanded into some self-service features, with more storage and basic query answering. Looker has tried to offer something similar, including some semi-structured data handling capabilities.
None of them are plug-and-play solutions. They’re built for technical people to do technical tasks.
NLQ can bridge that technical capability gap for business users. Here's why we see structured data as the most effective information source a data team can choose to fuel their chosen NLQ solution.
First, a quick recap
Structured Data
Relational, discreet and fits in a predetermined data model. Often tabularised.
Examples
CSVs, SQL databases, POS data. Almost always short, discreet, textual and/or numeric.
Unstructured Data
Larger, contextual, non-standardised and impractical to tabularise due to its inconsistent nature.
Examples
Audio or videos, long-form documentation, images, blogs, PDFs, social media streaming, geographic data, and search engine queries.
Why we target structured data
If you ask us, structured data is the truest way to calculate a deep, holistic view of a business.
Many of the most requested business performance metrics are calculated with it:
A marketing team can calculate the Customer Acquisition Cost of a new campaign.
A product team can work out the Customer Lifetime Value of their latest product release.
A sales team can understand their Lead-to-Customer Ratio for a specific period of time and make strategic decisions based on actual data.
HR teams can better understand their hiring process, from time-to-hire to training cost per employee.
Structured data is tabularised, using shared, custom definitions and metrics provided by a data team. The uniformity and relational nature of clean, structured data is at its most tangible when plugged into models like Fluent. When a user asks a question, text-to-SQL models can understand the shared context of the data available and clarify the query before answering.
Of all the applications of natural language solutions, we find the most consistency and immediate value-add using structured data. Generating insights manually is labour-intensive and time-consuming for analysts. The queries are conversely time-sensitive and focus on gaining quick, short-term advantage. It leads to a short-sighted data culture that shackles data analysts to answering repetitive queries. This limits non-technical users to ad-hoc querying, with only surface-level exploration of their own data.
TL;DR
Automating ad-hoc structured data analysis is incredibly valuable to an enterprise business model. Complex, expensive BI tools and generic, off-the-shelf chatbots will not enable true self-serve insight on a non-technical level.
Additional benefits of building on structured data
Less Data Preprocessing (launch faster)
Minimal preprocessing required because the data is already in a consistent format.
Data can be easily cleaned, filtered, and transformed.
Easier Data Integration (less development headaches)
Integration with BI tools is straightforward due to the standardised nature of the data.
Query languages like SQL can be used to retrieve and manipulate data efficiently.
Faster Model Training (launch *even* faster)
Machine learning models can be trained on structured datasets with clear features and labels.
Data teams can apply definitions and guardrails in SQL to tailor answer generation.
Higher Performance and Accuracy (use with confidence)
High accuracy and performance due to the clear structure and organisation of data.
Easier to validate and interpret results.
How Query Augmentation supercharges structured data
“95% of questions are some version of something that has already been asked and answered in the past.”
We hear this sort of thing a lot during client calls - the above is a verbatim quote from one of our clients, a major global consultancy. Data teams are aware that they’re retracing steps when answering most ad-hoc questions. They might produce hundreds, if not thousands, of dashboards to try and reduce that workload. Fluent’s Query Augmentation, leveraging historic SQL queries in your data warehouse, doesn’t make answer generation faster. It becomes richer, more insightful and consistent, too.
Rather than repeating queries becoming a drag on a data team, they now become an efficiency driver, contributing to more consistent, enlightening conversations with the user.
Structured data certainly packs a punch for only making up roughly 10-20% of the data the average business produces.
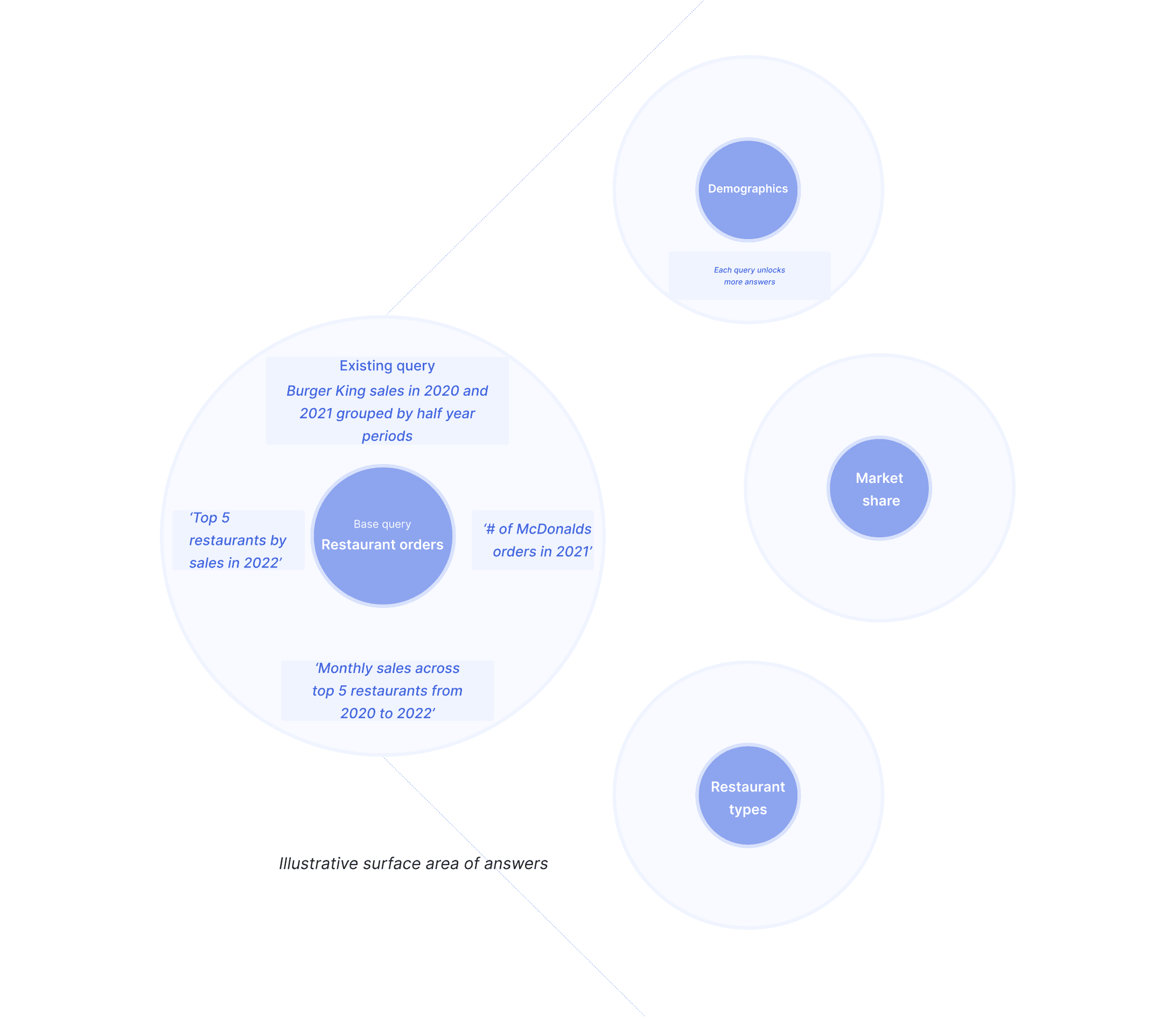
The equivalent for unstructured data would be more unpredictable, lengthy and require a lot more development to achieve. Platforms like ChatGPT, Chatbase and Mendable’s chatbots tend to vaguely revise, summarise or classify unstructured data, instead of actually understanding its wider context and expanding on the data during conversation.
Conclusion
Which of your data offers the most value through BI enhancements? It’s easy to think that the largest proportion - your nuanced, unstructured data - must be. We see it differently.
Which datasets cause your data team the most headaches?
Which data is hardest to read without technical knowledge?
Which data is relied upon most often to answer basic, quantitative questions?
Structured data queries dominate your data team’s time, constantly being translated and manipulated to provide critical context.
AI-powered text-to-SQL solves that problem, and turns a SQL database into an intelligent, conversational layer any user can pick up and interact with from day one.
If we’ve piqued your interest with the above, and you'd like to learn more about how text-to-SQL could change your internal data culture, drop us a line at the link below:
Request a Fluent demo
To download our research white paper for free - ‘The reality of building a text-to-SQL solution in-house’ - head here.
Work with Fluent
Put data back into the conversation. Book a demo to see how Fluent can work for you.
10 February 2025
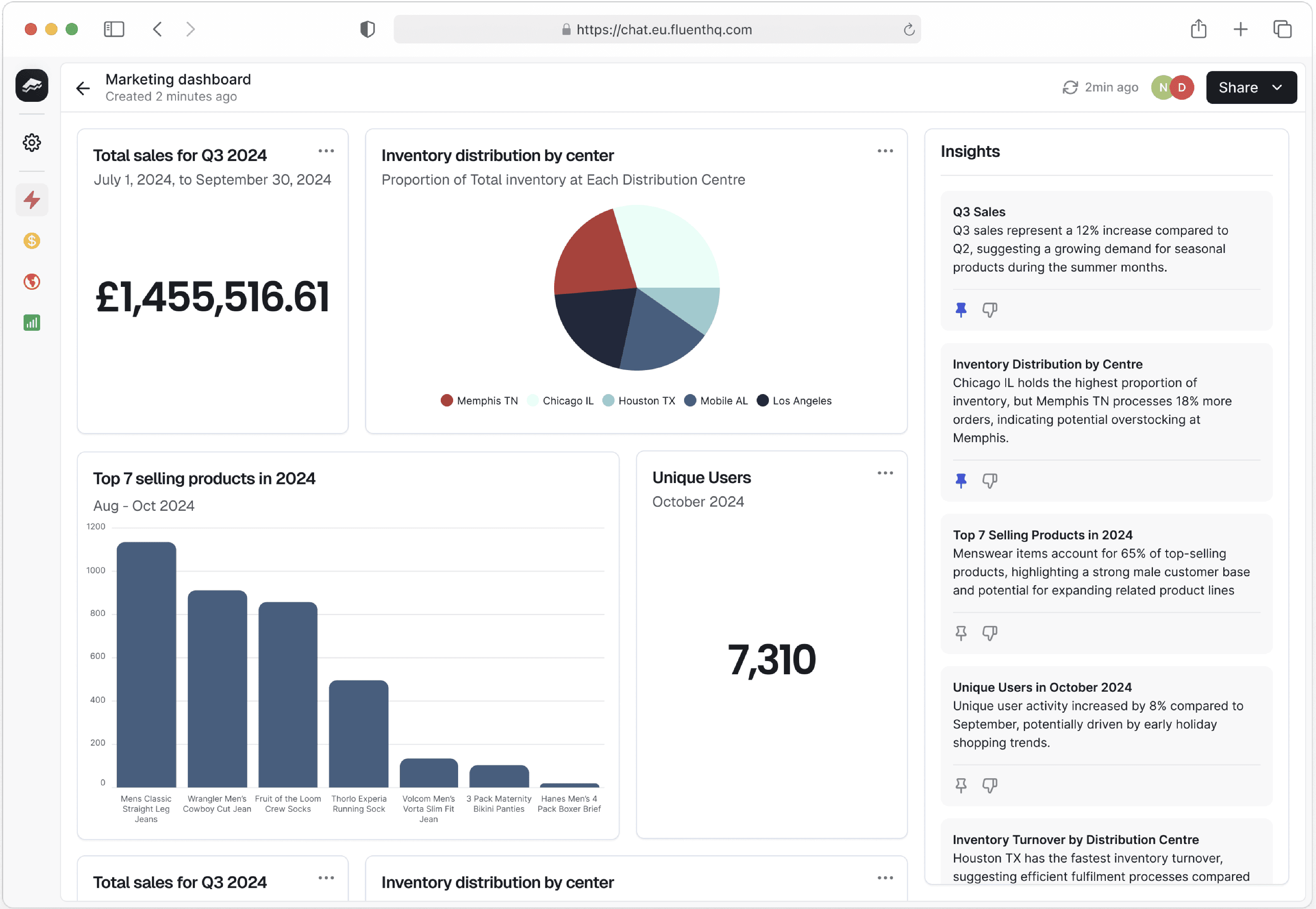
Introducing dashboards
3 February 2025
Fluent Text-to-SQL: Fast, Accurate AI Data Querying
Stay up to date with the Fluent Newsflash
Everything you need to know from the world of AI, BI and Fluent. Hand-delivered (digitally) twice a month.
