
Many text-to-SQL models have been put through their paces on the Spider 1.0 test. The Yale Spider 1.0 (and the recently released Spider 2.0) were created to stress-test natural language processors and demonstrate their accuracy and effectiveness. At least, that was the idea.
Spider 1.0 has been around for a while, but we’ve reviewed Spider 2.0, too. In essence, it seeks to push LLMs even further. 2.0 will challenge a model’s GUI (graphical user interface) control, a much harder task than purely writing SQL (the highest 2.0 scores only show a 14% success rate so far).
Some models will refer to high Spider test scores to demonstrate innate quality. But here’s the thing.
The Spider test won’t tell you much at all.
Scoring ‘high’ on the spider test (80/85%+) will tell you one thing: the LLM is very good at answering the sample questions featured in *the spider test*. That’s about it.
Over-simplistic questions and overfit models limit query structures or schemas to score highly. It’s a benchmark focused on Exact Set Match evaluations to reference queries. These queries lack natural language’s syntactic ambiguity. Even a model with a 99% score on the Spider benchmark won’t necessarily be 99% effective in a real-world setting.
There are many of these kinds of tests too. Some focus on specific logic, subject matters, multiple domains, multi-turn interactions or large datasets. Ultimately, they’re borderline vanity metrics in the text-to-SQL industry.
For enterprise businesses wanting to understand the ‘effectiveness’ of a potential text-to-SQL solution, you need to introduce your own data in a pilot process.
What makes a good testing process for a text-to-SQL model?
A model should be tested on real-world samples of your data warehouse and field historic or realistic queries from your team to ensure it can handle the complexity and variability of practical applications, particularly from non-technical business users.
Running regular user studies and feedback loops can provide insights into the model’s effectiveness in real-world scenarios.
Consistency over accuracy
Consistency builds trust, and you will need non-technical users to trust a third-party LLM that you choose to integrate your warehouse into. Models will display incorrect answers, but it’s not always their ‘fault’. Two business queries can be semantically the same, but use totally different syntax:
Query 1 - Direct filtering using the WHERE clause
SELECT *
FROM employees
WHERE department = 'Sales';
Query 2 - Joins the employees table with a hypothetical departments table and then filters based on the department name.
SELECT employees.*
FROM employees
JOIN departments ON employees.department = departments.name
WHERE departments.name = 'Sales';
The answer to both queries would be all employees in the Sales team, but they approach it in different ways, and LLMs will have to learn that context. Poor data quality, edge cases and large, changeable data warehouses can contribute to inaccurate outputs. What you want to see from a model, above all else, is consistency in behaviour and logic flows for the most common queries, which, anecdotally speaking, can make up over 90%+ of ad-hoc queries a data team receives. With a predictable model, you can train it quicker, run it on best practices, and manually intervene to solve any misfires.
Additional Testing Criteria
Context Handling
An effective model should handle multi-turn interactions and maintain context with queries reminiscent of real-world use conversation. This can be worked into a pilot by asking multi-step questions, intentionally open-ended queries and using terminology specific to your dataset.
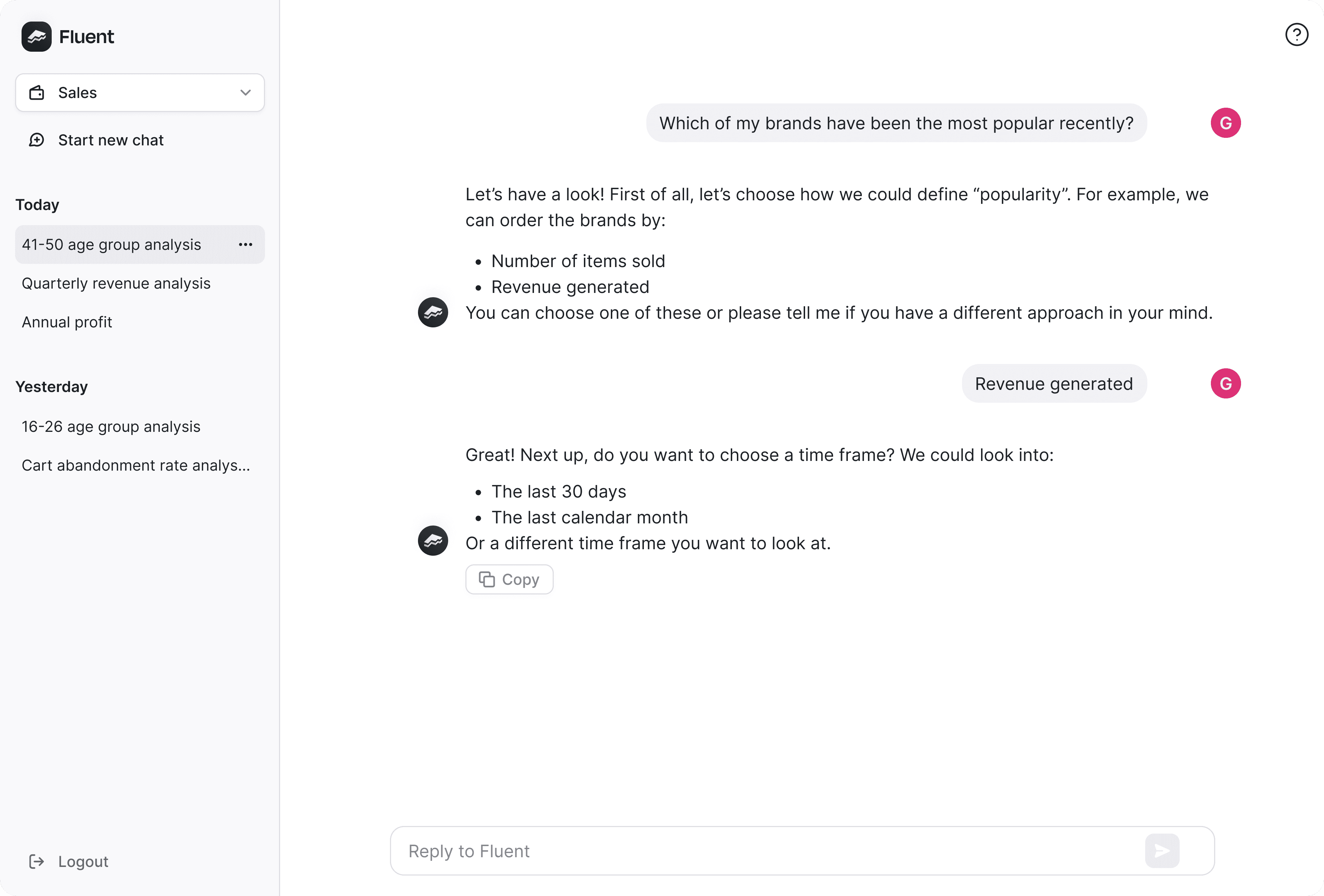
Error Handling and Ambiguity Resolution
A good model should be able to handle ambiguous inputs gracefully and provide meaningful error messages or clarifications when needed. Trialling the model with several different non-technical and technical users exposes the model to your authentic linguistic ambiguity.
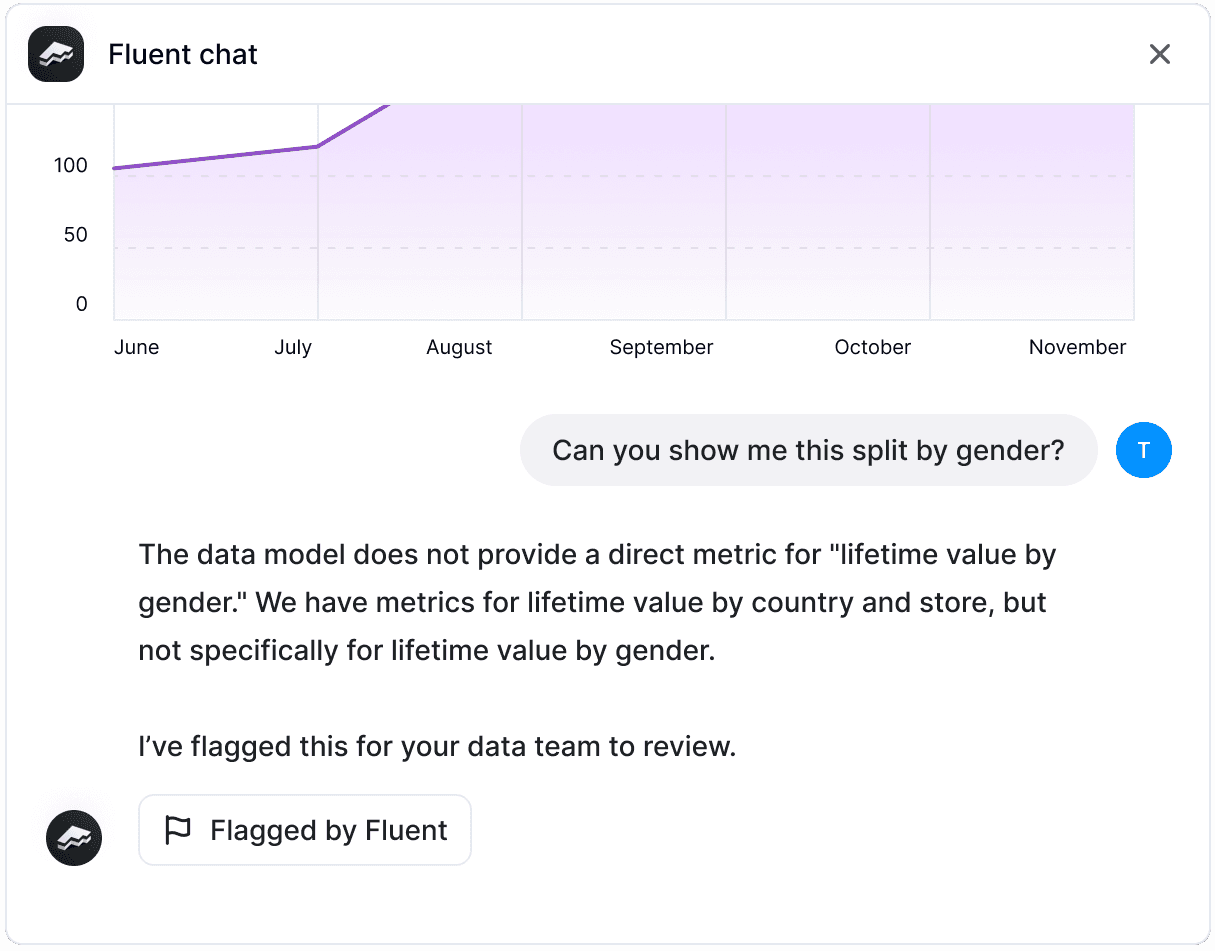
Performance and Scalability
A model should be able to efficiently refer to SQL queries, best done through a semantic layer (Fluent's is based on metrica, pictured below) that performs well even on large datasets. Therefore, a structured pilot process should include exposure of the model to, ideally, a large portion of your real-world, structured data.
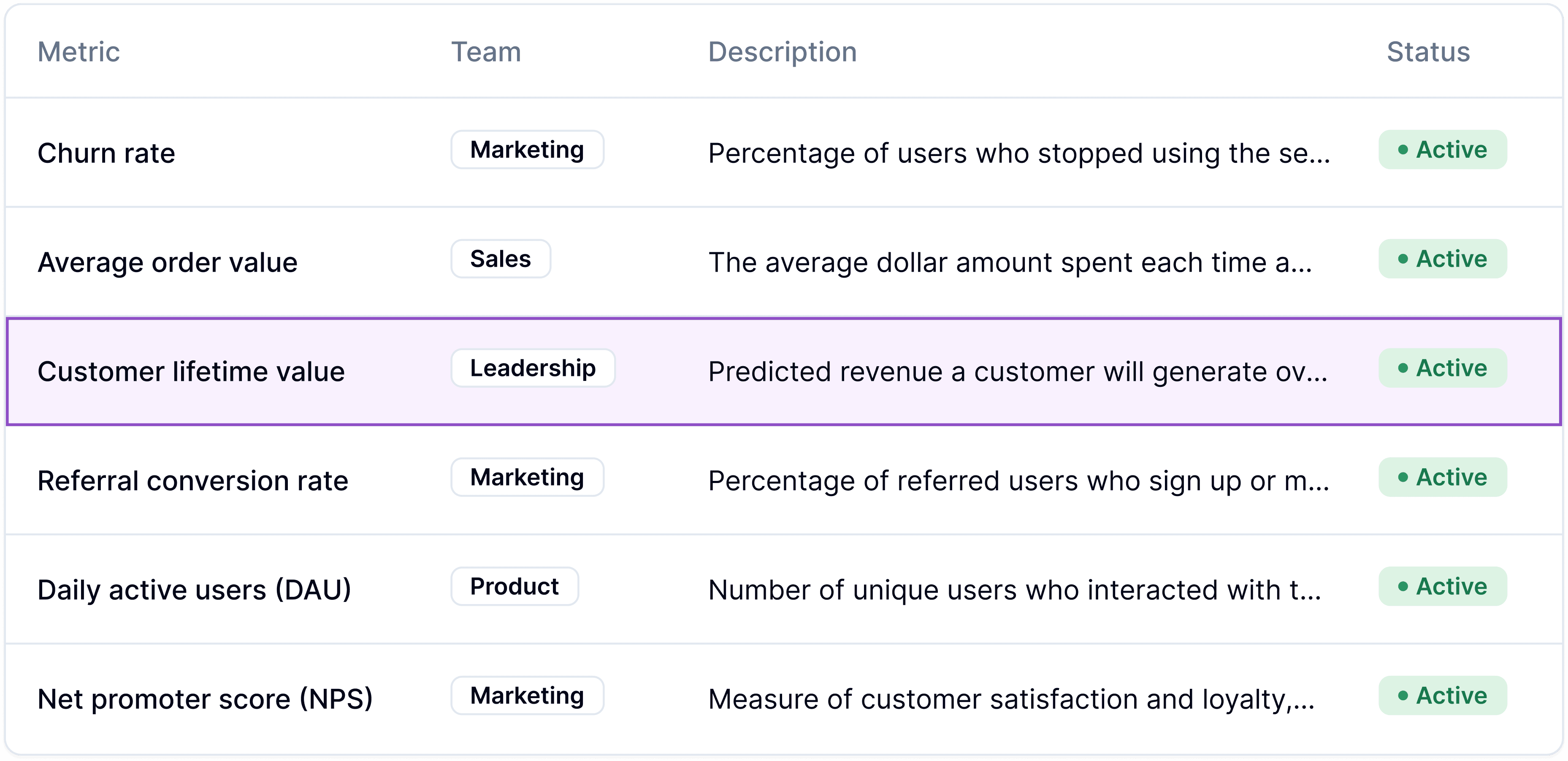
Flexibility and Adaptability
Test the model on cross-domain data, such as sales, customer, and inventory metrics. ‘Zero-shot’ learning (inputting previously unseen data into the LLM) lets you assess a model’s generalisation abilities, too.
TL;DR
Text-to-SQL challenges like the Spider test provide a starting point for evaluating and improving semantic parsing models, but they don’t mean much to a data solution procurement exercise.
Focus on testing LLMs on real queries and prioritise chat features that generate consistent answers and clarification flows. Ultimately, the more historic SQL queries and datasets you expose a potential model to, the greater the surface area of questions it can answer and the more value your business users will derive from it.
If we’ve piqued your interest with the above, drop our team a line at the link below.
Get in touch
To read, or download, part one of this content series - our research whitepaper ‘The reality of building a text-to-SQL solution in-house’ - head here.
To read our previous blog ‘Why structured data is the key to self-serve business insights’, click here.
Work with Fluent
Put data back into the conversation. Book a demo to see how Fluent can work for you.
10 February 2025
Introducing dashboards
3 February 2025
Fluent Text-to-SQL: Fast, Accurate AI Data Querying
Stay up to date with the Fluent Newsflash
Everything you need to know from the world of AI, BI and Fluent. Hand-delivered (digitally) twice a month.
